
7. Fermat: sistema para la enseñanza de matemáticas
https://doi.org/10.52501/cc.096
Karina Mariela Figueroa Mora
María Lucía Barrón Estrada
Ramón Zatarain Cabada
Dimensions
7. Fermat: sistema para la enseñanza de matemáticas
La computación afectiva es uno de los tópicos más influyentes en los diferentes campos del aprendizaje y representa una de las áreas de interés más activas en las conferencias sobre tecnologías del aprendizaje, como en los siguientes eventos internacionales: Intelligent Tutoring Systems Conference (its), Artificial Intelligence in Education (aied), e International Conference in Advanced Learning Technologies (icalt). El tema de tecnologías inteligentes y afectivas para el aprendizaje involucra a investigadores de diversos campos como computación, inteligencia artificial, psicología y pedagogía. En las últimas dos décadas, un número creciente de sistemas tutores inteligentes y afectivos han sido desarrollados para apoyar la enseñanza en diferentes campos de estudio (Hasan et al., 2020; Petrovica et al., 2017).
La investigación en el área de computación afectiva incluye tanto la detección de emociones de los usuarios como la respuesta que los sistemas emiten a partir de ellas. Los sistemas de detección de emociones son capaces de captar diversas señales que emite el usuario a través del rostro, el habla, la conversación escrita y otros rasgos humanos que comunican estados emocionales como frustración, interés, aburrimiento, entre otros. Estos sistemas reciben señales de sensores como cámaras web (Essa & Pentland, 1995; Yacoob & Davis, 1996), micrófonos (Tosa & Nakatsu, 1996) y texto a través de diálogos conversacionales (Graesser et al., 2004), entre otros. Por otra parte, los sistemas de reconocimiento de emociones implementan formas eficientes para gestionar las emociones negativas del estudiante (Arroyo et al., 2009; D’Mello et al., 2007; Boulay, 2011).
En este capítulo se presenta un sistema al que se integraron redes sociales de aprendizaje, sistemas tutores inteligentes y computación afectiva para la enseñanza de las matemáticas. Un sistema tutor inteligente fue incorporado a una red social de aprendizaje llamada Fermat. Este sistema se desarrolló con el objetivo principal de apoyar a los estudiantes mexicanos a mejorar sus resultados en la Evaluación Nacional del Logro Académico en Escuelas de México (enlace1). La prueba enlace es una evaluación estándar del sistema de educación nacional en la que participan estudiantes de educación básica (primaria y secundaria). En 2011, 14 millones de niños de primaria y secundaria participaron en la prueba y los resultados revelaron que más de nueve millones de ellos tienen un nivel insuficiente en aprendizaje en matemáticas.
7.1 La enseñanza de matemáticas en México
En México, un estudiante de educación básica (primaria) asiste durante 40 semanas a clases, acumulando un aproximado de 800 horas de clases al año. El número de estudiantes por grupo ha disminuido en los últimos años; actualmente cada maestro de nivel primaria atiende en promedio a 25 estudiantes (sep, 2021). En la figura 37 se presenta un ejemplo del número de horas lectivas en el ciclo escolar 2011-2012 para los estudiantes de tercer año de primaria.
De esta cantidad de horas en el ciclo escolar 2011-2012, un profesor impartía un promedio de 7.2 diferentes áreas o materias a los estudiantes. Los maestros deben seguir el programa de estudio oficial que contiene los temas de estudio y algunas recomendaciones de cómo enseñar los contenidos. A continuación, se describen dos pruebas que se aplican a nivel nacional e internacional para medir el nivel de conocimiento que poseen los estudiantes de educación básica.
Figura 37. Horas lectivas de estudiantes de tercer año de primaria

Fuente: DOF (2011).
Prueba ENLACE
La Evaluación Nacional de Logro Académico en Centros Escolares (enlace) se aplicaba anualmente tanto en planteles públicos como privados, con el fin de medir el nivel de dominio en las áreas de español, matemáticas y una tercera materia académica que difiere cada año. En la figura 38 se muestran los resultados de la prueba aplicada desde 2006 hasta 2011.
Figura 38. Porcentaje de resultados 2006-2011
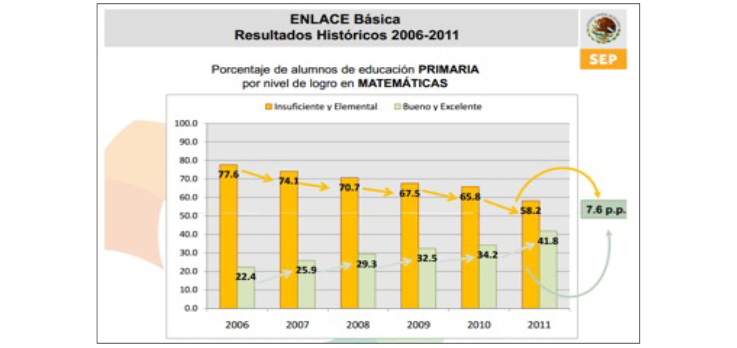
Fuente: enlace (2011).
Aunque los resultados de la prueba enlace, como se observa en la figura 38, mejoraron con los años, los estudiantes catalogados con conocimiento Insuficiente y Elemental son la mayoría (58.2% en 2011), mientras que solo 41.8% está en los niveles Bueno y Excelente. Se aprecia un bajo rendimiento de los alumnos de primaria en matemáticas, lo que subraya que se realicen cambios en las estrategias de enseñanza para poner un mayor énfasis en el individualismo del aprendizaje.
Prueba PISA
El Programa Internacional de Evaluación de Estudiantes (pisa, por sus siglas en inglés) es un estudio periódico y comparativo que promueve y organiza la Organización para la Cooperación y el Desarrollo Económico (oecd por sus siglas en inglés), y en ella participan los países miembros y no miembros (asociados) de la organización. Esta prueba se aplica cada tres años desde 1997 y en México desde el año 2000.
En esta evaluación participan estudiantes de 15 años de más de 60 países en el mundo. pisa tiene la tarea de evaluar tres áreas: matemáticas, ciencias y lectura. Con esta prueba se busca conocer en qué medida los estudiantes de 15 años han adquirido los conocimientos y habilidades necesarios para participar activa y plenamente en la sociedad moderna. La figura 39 presenta la tendencia en el desempeño de los estudiantes mexicanos de 2000 a 2018.
Figura 39. Tendencias en el desempeño en lectura, matemáticas y ciencias
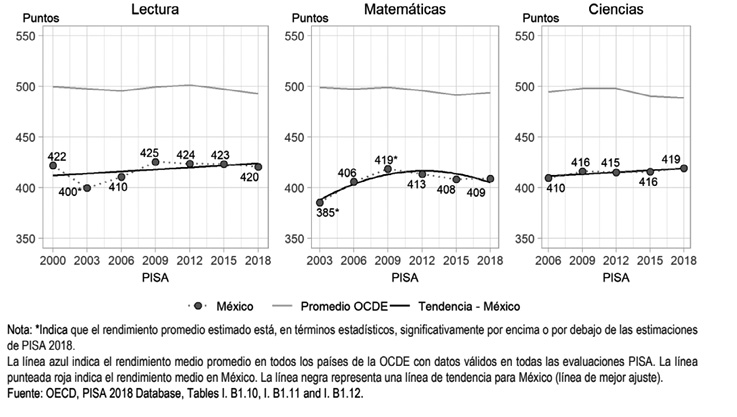
Como se puede apreciar en estos resultados, la tendencia en todas las áreas de evaluación no presenta una mejora significativa a través de los años, y los resultados de los estudiantes mexicanos están muy por debajo de la media de los países de la ocde. Esto indica que los estudiantes mexicanos están en desventaja para resolver situaciones que se les presenten en la vida real. La educación básica debe proporcionar bases sólidas para que los estudiantes sean capaces de enfrentar situaciones de este tipo y demuestren competencias para desempeñarse favorablemente en la vida real.
Los resultados que se muestran en las pruebas de enlace y pisa son un indicio de la deficiente formación de los alumnos en un área primordial como las matemáticas.
7.2 ¿Qué es Fermat?
Fermat es una aplicación web que se compone de dos elementos principales: una red social de aprendizaje y un sistema tutor inteligente (sti). La red social de aprendizaje es un espacio social en la web donde los diferentes miembros de la red (profesores, estudiantes y padres de familia) comparten los recursos y funcionalidades que una red social otorga. Por otra parte, el sti permite al estudiante aprender matemáticas de una manera personalizada, como lo lleva a cabo un tutor humano, aplicando técnicas vanguardistas de computación afectiva para considerar no solo aspectos cognitivos del estudiante, sino también estados emocionales o afectivos.
Para llevar a cabo la evaluación de los elementos cognitivos del alumno, se implementó un sistema experto, el cual facilita la elección del siguiente ejercicio del estudiante, considerando el aprendizaje o conocimiento que haya logrado. Respecto a los elementos afectivos, Fermat realiza el reconocimiento de emociones del estudiante captando señales a través de una cámara (imagen del rostro) y un micrófono web (audio de voz). El estado emocional captado es importante para tomar decisiones cuando se selecciona un ejercicio que debe ser resuelto por el estudiante. Para esto, Fermat se apoya en un agente pedagógico, el cual interactúa con el alumno.
7.3 Análisis, diseño e implementación de Fermat
Al igual que con los dos proyectos de software presentados en los capítulos 5 y 6 (educa y Zamná), para el desarrollo de la herramienta Fermat se aplicó principalmente una metodología orientada a objetos. Antes de aplicar esta metodología, se realizó una investigación de los métodos más comunes y populares en la enseñanza de los temas de multiplicación y división de números enteros, correspondientes al tercer año de primaria. Este análisis generó como producto la especificación de requerimientos para el desarrollo de dos sistemas tutores inteligentes inmersos dentro de Fermat, los cuales se encargan de enseñar estos temas (multiplicación y división de números enteros). La etapa de análisis es de vital importancia para el desarrollo de cualquier aplicación de software, puesto que es donde se colocan las bases o fundamentos de todas las etapas posteriores de esta metodología.
Análisis de requerimientos
Esta etapa proporciona información del contexto del problema para identificar y establecer el comportamiento que va a tener el sistema y delimitar su funcionalidad.
Respecto a la red social de aprendizaje, las funcionalidades definidas coinciden con los de sistemas similares (redes sociales); para la herramienta Fermat, estas son:
- Cuentas de usuario.
- Comunidades.
- Cursos.
- Enlaces de amistades.
- Envío de mensajes.
Estas funcionalidades se mapean en un conjunto de requisitos que se clasifican en funcionales y no funcionales. En la tabla 6 se muestra la lista principal de requisitos funcionales de la red social de aprendizaje Fermat.
Tabla 6. Requisitos funcionales de la red social de Fermat
| ID | Requisito |
| R1 | El usuario debe poder crear cuentas de usuario |
| R2 | Los usuarios podrán iniciar y finalizar sesión |
| R3 | Los usuarios podrán agruparse en comunidades |
| R4 | Los usuarios podrán enviar, recibir, eliminar y tener un historial de mensajes |
| R5 | Los usuarios podrán tomar cursos y exámenes |
| R6 | Fermat deberá almacenar el historial de calificaciones y cursos de los estudiantes |
| R7 | Los usuarios podrán invitar, agregar y eliminar amigos |
| R8 | Los usuarios podrán conocer la ubicación actual de ellos y sus amigos |
Respecto a los sistemas tutores inteligentes, la tabla 7 expone algunos de los requisitos establecidos que deben estar presentes.
Tabla 7. Requisitos del sistema tutor inteligente
| ID | Requisito |
| R9 | Procesar de manera secuencial la resolución de operaciones de multiplicación y división |
| R10 | Identificar errores a través de las casillas de entrada |
| R11 | Proporcionar ayuda dependiendo de la etapa de resolución de la operación |
| R12 | Medir el tiempo de resolución de la operación de manera interna |
| R13 | Adaptar la interfaz del tutor de acuerdo con el estilo de la red Fermat |
| R14 | Integrar al tutor inteligente un sistema experto difuso para que ajuste la dificultad en las operaciones de acuerdo con el desempeño del estudiante |
| R15 | Revisar en un determinado tiempo si la entrada del estudiante es correcta |
Una vez reunidos los requisitos funcionales de la red social y del sistema tutor inteligente, se desarrollan los escenarios de interacción entre los usuarios y el sistema, llamados “casos de uso”. Los casos de uso ayudan a representar las funcionalidades del sistema que están implícita o explícitamente en los requerimientos obtenidos en la actividad del análisis. Algunos de los casos de usos mapeados a requisitos funcionales se muestran en la tabla 8.
Tabla 8. Mapeo de Casos de Uso de Fermat a requisitos funcionales
| ID | Caso de uso | R1 | R2 | R11 | R12 | R14 |
| CU1 | Registrar usuario | X | ||||
| CU2 | Iniciar sesión | X | ||||
| CU15 | Proporcionar ayuda | X | ||||
| CU16 | Cambiar dificultad en problema | X | X |
Diseño de Fermat
Una vez detectados los principales requerimientos o requisitos de todo el software, se procedió a realizar el diseño. La figura 40 muestra un esquema general de Fermat, incluyendo la red social y los dos sistemas tutores inteligentes.
Figura 40. Esquema de los elementos de Fermat
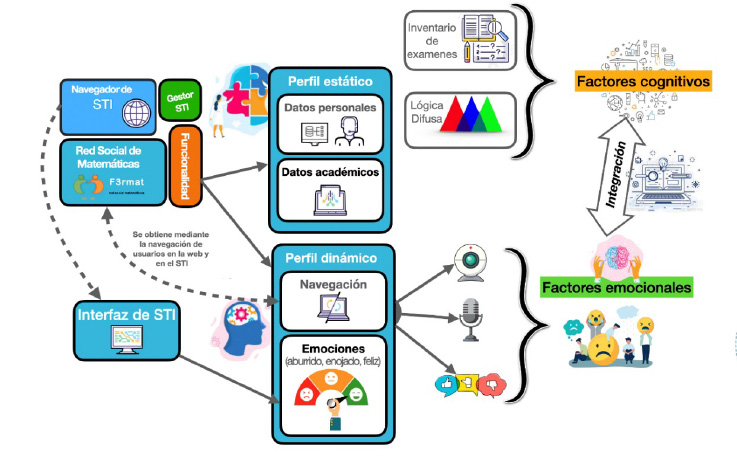
Como se puede apreciar en la figura 40, un usuario accede a la red social mediante un navegador como Explorer, Firefox o Chrome. El usuario cuenta con dos perfiles: uno estático, el cual contiene datos personales (nombre, correo, edad, etc.) y académicos (escuela, cursos, calificaciones, etc.), y otro dinámico, el cual mantiene información en tiempo real de aspectos emocionales (aburrido, frustrado, motivado, etc.) y cognitivos (resultados, tiempo, y errores en ejercicios). Los datos almacenados en estos perfiles se captan durante la interacción del usuario con el sistema de distintas fuentes. Los datos del perfil estático se obtienen cuando el usuario se registra a la red social o cuando resuelve el examen de valorización de matemáticas. Los datos del perfil dinámico se obtienen de exámenes en línea, como el Felder-Soloman (Felder & Soloman, 2004), de ejercicios (tiempo, ayudas y fallas) y desde dispositivos como la cámara web y el micrófono. Con estos datos (emociones, tiempos, errores o fallas, etc.) un sistema difuso toma la decisión del grado de complejidad del siguiente ejercicio.
Una vez ingresado a la red social, el usuario puede acceder a los sistemas tutores inteligentes, como se aprecia en la misma figura 40. El tutor cuenta con su propia interfaz para que el estudiante ejercite distintas operaciones de multiplicación y división en niveles que dependerán de su habilidad para resolver los ejercicios (nivel de conocimiento). Este nivel se asigna al inicio por medio de un examen de conocimientos, pero después se calcula dinámicamente por el sistema difuso que contiene el tutor.
Los diferentes módulos de la red social se distribuyeron para conformar la arquitectura de software del sistema que se presenta en la figura 41.
Figura 41. Arquitectura de software para Fermat
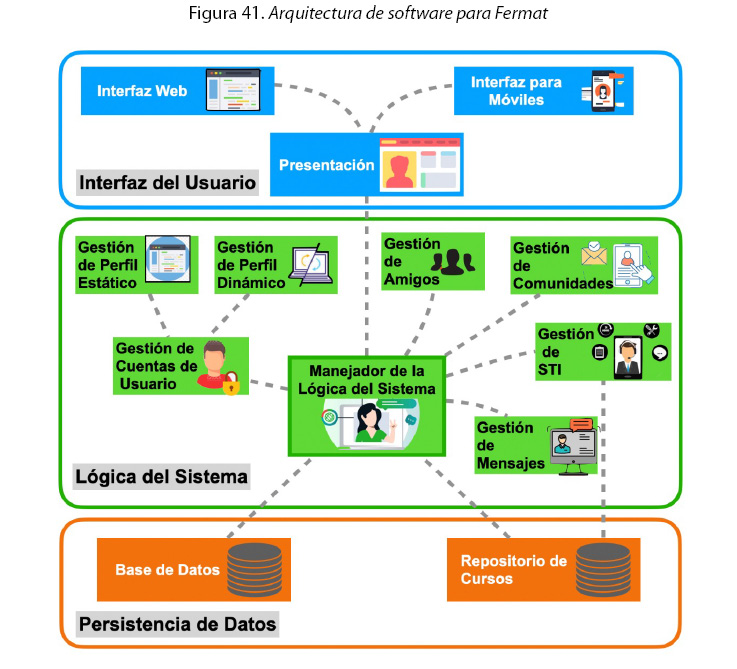
Se utilizó el modelo arquitectónico de capas de abstracción con tres capas: Interfaz del Usuario, Lógica del Sistema y Persistencia de Datos. Este diseño arquitectónico en capas permite dividir los componentes del sistema en diferentes niveles de abstracción y desarrollar de forma independiente cada uno de ellos. Las capas sólo pueden interactuar con sus capas adyacentes, lo que permite mantener la consistencia en los datos; además, mientras se respeten las interfaces de comunicación entre capas, los cambios realizados en una capa no afectan a las demás.
Se propuso este estilo arquitectónico debido a su soporte para adecuarse a los cambios, para que las futuras modificaciones a la red social puedan desarrollarse sin afectar a los demás componentes; además, permite tener un mejor control sobre la persistencia de los datos y la seguridad de estos.
Estructura del sistema tutor inteligente
La estructura del sistema tutor inteligente (sti) respeta el modelo tradicional de un sti, el cual contiene cuatro componentes: una interfaz de usuario encargada de la comunicación entre el usuario y los otros tres componentes llamados módulos, que son: dominio, estudiante y tutor. El sistema también cuenta con un módulo que realiza el reconocimiento de emociones y las comunica al sistema. La figura 42 muestra la estructura completa del sti de Fermat.
Figura 42. Estructura del STI de Fermat
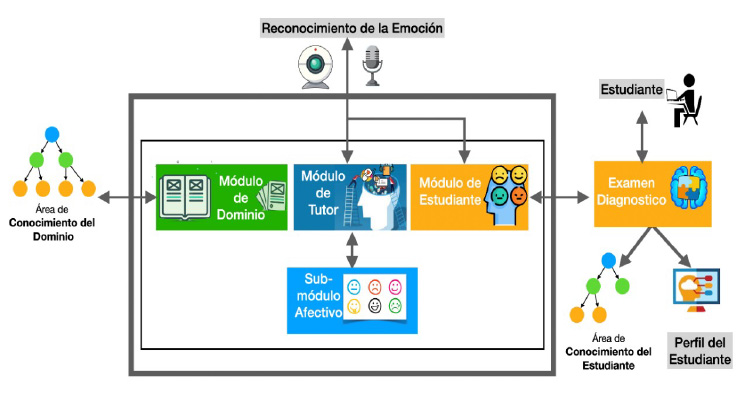
A continuación, se describe la función e implementación de cada uno de los módulos.
Módulo de Dominio: Este módulo contiene todo el conocimiento del dominio del experto, en este caso correspondiente a los métodos de solución de multiplicaciones y divisiones de números enteros que se enseñan en tercer año de primaria. El conocimiento se implementó como un árbol en donde la raíz representa el conocimiento total de la operación (por ejemplo, la operación división), sus ramas representan los capítulos y las hojas vienen a ser los temas. La totalidad de los nodos en el árbol de conocimiento representa el conocimiento del módulo de dominio (experto).
Los temas que conforman al curso se encuentran almacenados en un archivo en formato XML con diferentes etiquetas para cada elemento del curso:
<curso> </curso> delimitan el contenido del curso
<nombre></nombre> define el nombre del curso que se creó
<temas></temas> delimita el contenido del curso por temas.
Para cada tema se definieron tres etiquetas como se muestra a continuación:
<tema id = “número”> </tema> define el número de tema del curso
<urlCurso></urlCurso> define la dirección url del tema del curso
<urlExamen></urlExamen> define la dirección url del examen de un tema del curso.
Un ejemplo de la estructura del archivo xml del curso con las etiquetas mencionadas se muestra a continuación:
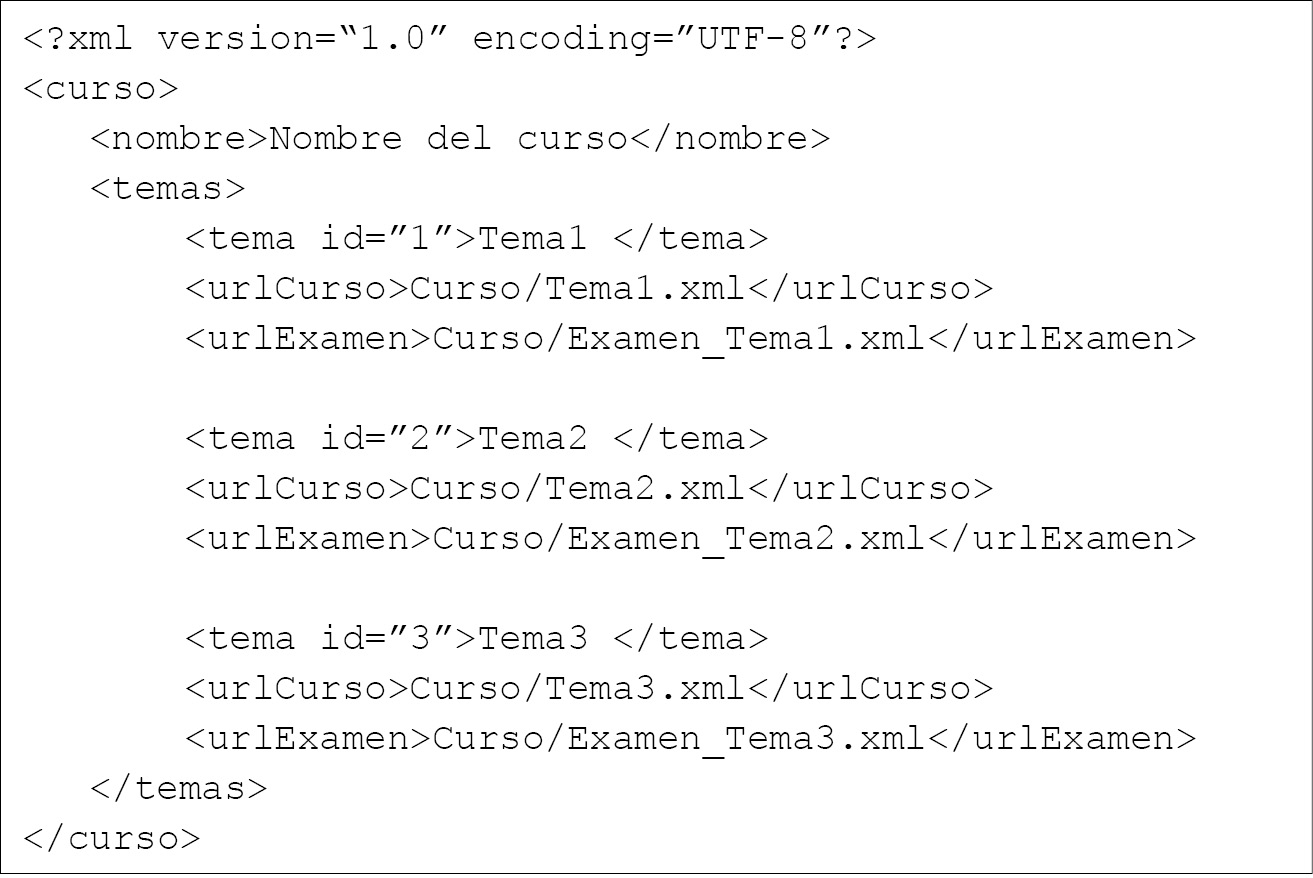
Cada tema tiene asociada la url donde está almacenado el contenido del tutor inteligente de cada tema del curso y el examen de diagnóstico para conformar, a través del módulo del estudiante, sus perfiles.
Módulo de Estudiante: El módulo del estudiante de Fermat contiene toda la información del estudiante. Por una parte, se representa el conocimiento que tiene el estudiante, el cual puede ser visto como un subárbol de todo el conocimiento que el experto posee (área de conocimiento del estudiante), y por otra contiene también la información de los perfiles (estático y dinámico) del estudiante. El módulo del estudiante aplica un examen diagnóstico al estudiante la primera vez que accede al sti con el fin de evaluar el desempeño del estudiante y determinar sus habilidades cognitivas y de razonamiento. Los resultados del examen muestran lo que el estudiante sabe y lo que necesita aprender, y esta información se representa en el árbol de conocimiento (dominio) del estudiante. Toda la información personal y académica del estudiante se almacena en el perfil del estudiante.
Para determinar el grado o nivel de conocimientos del estudiante, se implementó un examen diagnóstico. El contenido del examen se almacena en un archivo xml con la siguiente estructura:

Cada pregunta tiene asignado un nivel de dificultad que se usa para determinar la ponderación de cada respuesta en la evaluación. En este caso, las preguntas difíciles tienen un valor de 3 puntos, las normales de 2 y las básicas de 1 punto.
Para la calificación (valor entre 0 y 1), se utiliza la siguiente ecuación:
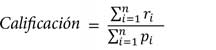
donde:
ri representa los puntos de cada respuesta correcta del examen,
pi representa los puntos asignados a cada pregunta del examen.
El sistema determina el resultado del examen, y con éste un algoritmo obtiene el nivel de aprendizaje del estudiante y el método de enseñanza que se debe utilizar.
El algoritmo para asignar el nivel y método (“Lattice” o tradicional) para el aprendizaje del estudiante en la operación de multiplicación, se presenta a continuación.

Para la representación del conocimiento del estudiante se usaron dos categorías:
- Temas. Cada vez que el estudiante accede a un tema, este se almacena en el historial de temas visitados por el estudiante.
- Experiencia del estudiante. Almacena el historial de las calificaciones obtenidas en los exámenes que el estudiante ha respondido por materia.
Módulo de Tutor: El módulo tutor del sti está construido siguiendo dos modelos. El primero está basado en la teoría de cognición de act-r (Anderson et al., 1990). Este tipo de sistemas tutores son llamados “tutores de modelo-seguimiento”, donde al estudiante se le enseña cada acción que debe realizar paso a paso. El segundo modelo se apega más al módulo del estudiante, y muestra los posibles errores que se pueden cometer durante la solución de un ejercicio (Woolf, 2009). Estos modelos se eligieron porque se adaptan al proceso que se sigue para resolver una división de números enteros. Enseñar a resolver divisiones es un proceso que el estudiante debe conocer paso a paso, por lo que indicar los errores que se cometen durante el proceso es importante para que el estudiante aprenda de ellos. El módulo del tutor cuenta con el apoyo de dos submódulos adicionales:
- Reconocimiento de emociones: Las emociones se detectan utilizando las expresiones faciales y la voz. El método usado para la detección de emociones en rostro está basado en la teoría de Ekman, que distingue seis emociones básicas (ira, disgusto, miedo, felicidad, tristeza y sorpresa), a los cuales se agregó una más para representar un estado neutral.
- Manejo afectivo: La instancia de este submódulo es un agente afectivo que emite mensajes que ayudan al estudiante a sentirse acompañado, indica los errores que comete durante el curso y ofrece ayuda cuando el estudiante la solicita. Este agente animado se representa por el personaje llamado “Genio” que proviene del grupo de agentes implementados por Microsoft.
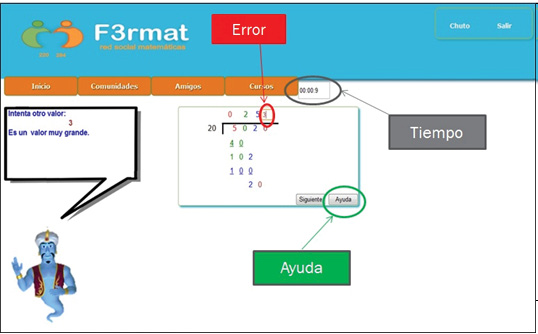
El módulo tutor fue implementado mediante una interfaz en HTML5 y JavaScript, y en él se reciben las respuestas del estudiante y se comprueban mediante un intercambio de datos a través de objetos xml para las multiplicaciones y json para las divisiones. La figura 43 muestra el mecanismo de evaluación del tutor para una operación de división. En la figura se puede observar que aparecen dos líneas de texto donde se despliega la información necesaria para verificar las respuestas del estudiante en cada paso y proporcionar ayuda, o bien habilitar el siguiente estado.
Figura 43. Mecanismo de evaluación del tutor
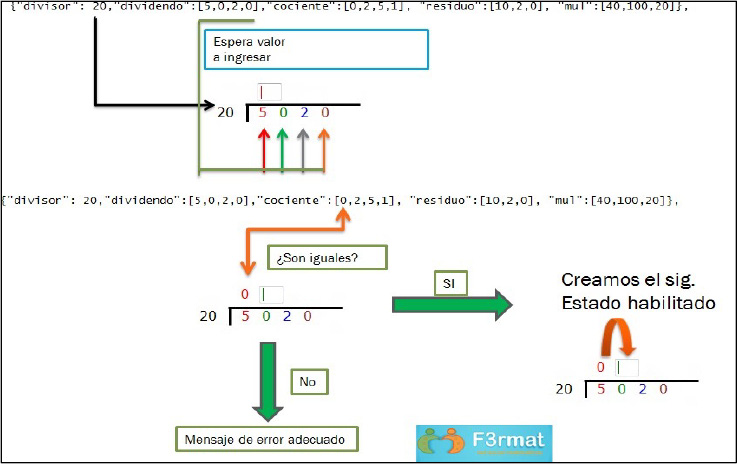
En este sistema se puede observar que el tutor espera que el usuario ingrese un valor usando la interfaz; posteriormente, el sistema verifica que sea correcto y activa la siguiente casilla para continuar el proceso con el siguiente valor. Cuando el usuario ingresa un valor erróneo, el sistema tutor utiliza al agente afectivo para enviar un mensaje sobre el tipo de error. Este flujo de interacción se repite hasta finalizar el proceso de la división. Durante este proceso el estudiante puede hacer uso de dos botones que se encuentran debajo del espacio de la operación de división que está resolviendo. El botón de Ayuda envía mensajes de retroalimentación al estudiante por medio del agente afectivo. El botón Siguiente tiene dos funciones principales: cambia de operación avanzando a la siguiente, independientemente de si la división actual está terminada o no, y también llama a ejecución al sistema experto difuso.
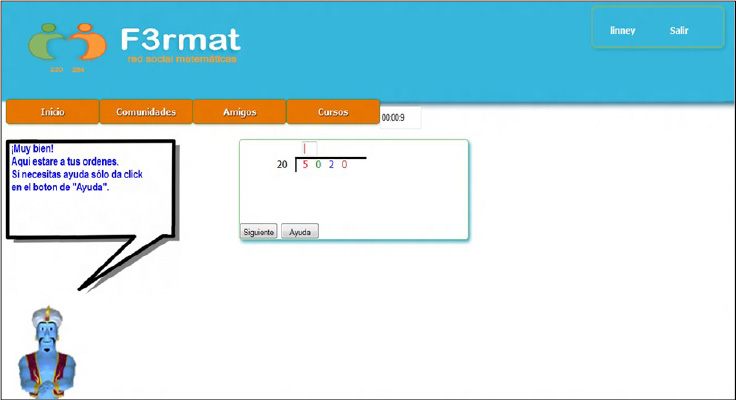
La figura 44 muestra la interfaz real que se presenta en Fermat para resolver operaciones de división. En la interfaz se puede apreciar al agente pedagógico Genio y un mensaje de retroalimentación, además se muestran también los botones de Ayuda y Siguiente. La figura del agente afectivo cambia de acuerdo con su respuesta, la cual busca ser cordial o afectuosa con el estudiante. Genio aparece cuando el estudiante comete un error o cuando este solicita ayuda.
Figura 44. Interfaz del tutor inteligente Fermat
7.4 Sistema experto difuso
Para realizar el trabajo de razonamiento o inferencia de los ejercicios que se presentan al estudiante de acuerdo con su nivel de conocimientos, se implementó un sistema experto difuso. Este sistema toma como entrada tres variables difusas que tienen que ver con el tiempo, el número de errores y el número de ayudas, las cuales se determinan en el ejercicio que se está resolviendo y con ellas genera un valor difuso de salida que es la dificultad del siguiente ejercicio. En cierta forma, el rendimiento del estudiante se ve reflejado mediante esas variables al estar resolviendo una operación. Las tres variables difusas de entrada mencionadas se señalan en la figura 45.
Figura 45. Las tres variables de entrada del sistema difuso
Los conjuntos difusos propuestos para cada variable lingüística son los siguientes:
- Error = {poco, normal, muchos}
- Ayuda = {poca, normal, mucha}
- Tiempo = {muy rápido, rápido, lento, muy lento}
- Dificultad = {muy fácil, fácil, básico, difícil, muy difícil}
En la figura 46 se muestran gráficamente los conjuntos difusos de cada una de las variables lingüísticas Error, Ayuda y Tiempo.
Figura 46. Conjuntos difusos de variables Error, Ayuda y Tiempo

Algunas reglas difusas definidas para determinar el grado de dificultad del siguiente ejercicio se muestran a continuación:

La tabla 9 muestra los valores difusos, y sus respectivos rangos, y valores normalizados para la variable difusa Dificultad.
Tabla 9. Valores difusos para variable Dificultad
| Variable Difusa | Rango de dificultad (%) | Valores normalizados |
| Muy fácil | 0% - 10% | 0 – 0.1 |
| Fácil | 0% - 30% | 0 – 0.3 |
| Normal | 20% - 80% | 0.2 – 0.8 |
| Difícil | 70% - 100% | 0.7 – 1.0 |
| Muy difícil | 90% - 100% | 1.0 |
7.5 Reconocimiento de emociones por medio de redes neuronales
El reconocimiento de afecto o emociones es una de la áreas más interesantes y prometedoras en el campo de los sistemas tutores inteligentes. La instrucción adaptada o personalizada originalmente tenía como principal objetivo usar la psicología y el análisis cognitivo para crear sti basados en el uso de computadoras (Carbonell, 1970; Clancey, 1979; Anderson et al., 1990; Aleven & Koedinger, 2002; Woolf, 2009). Sin embargo, Picard (1995) argumenta que, al observar las emociones del estudiante, un sistema computacional que enseña (sistema tutor) podría responder como lo haría un tutor humano, es decir, personalizando la enseñanza.
En los últimos años se ha observado un aumento en el número de sti sensitivos al afecto aplicados a diferentes campos de aprendizaje (Hasan et al., 2020; Petrovica et al., 2017). Un sistema que detecta emociones o afectos observa y estudia la cara, la voz, la conversación y otros elementos o características de un usuario, para enseguida detectar frustración, interés, aburrimiento u otras emociones (Essa & Pentland, 1995; Yacoob & Davis, 1996; Tosa & Nakatsu, 1996; Graesser et al., 2004). Por otra parte, un sistema responde a emociones buscando que el usuario transite de un estado emocional negativo a uno positivo.
Uso de una red neuronal para reconocimiento de emociones
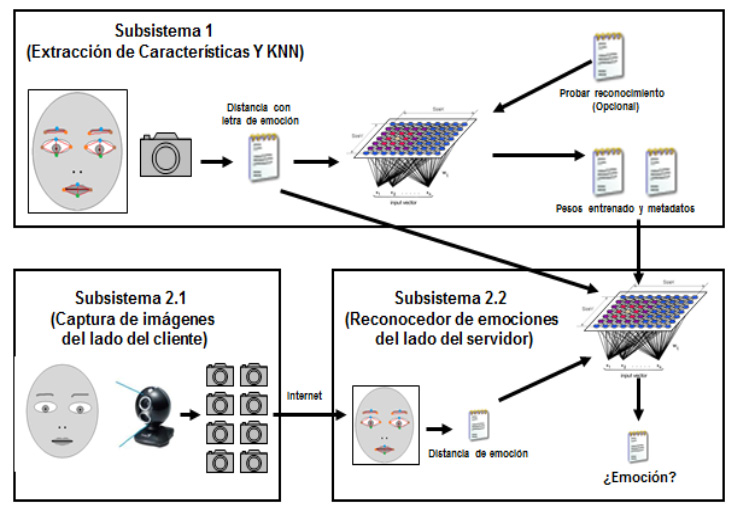
En Fermat las emociones se detectan por medio de la cara y a través de la voz y la conversación o diálogo. El algoritmo usado para detectar emociones en rostros se basa en la teoría de Ekman, la cual reconoce siete emociones básicas: enojo, disgusto, miedo, felicidad, tristeza, sorpresa y neutro (carente de emoción). El sistema reconocedor fue construido en tres subsistemas: el primero fue implementado para extraer características de rostros almacenados en una base de datos o dataset para ser usadas en el entrenamiento de la red neuronal. El segundo subsistema es la red neuronal de Kohonen, que se usa para reconocer emociones en rostros. Y el tercer subsistema integra a los dos primeros en un modelo cliente (extracción de características) y servidor (red neuronal para reconocer emociones). La figura 47 muestra todo el sistema de reconocimiento de emociones en rostro, el cual fue implementado en el lenguaje de programación Java con ayuda de las librerías OpenCV (Open Source Computer Vision) y JavaCV.
Figura 47. Sistema reconocedor de emociones
A continuación, se explica el algoritmo usado en el sistema.
Algoritmo de extracción de características
- Habilitar la captura de video a través de la cámara web.
- Detección de la cara. Aplicar la técnica Haar-like Features Cascades (Viola & Jones, 2001; Lienhart & Maydt, 2002), para la detección de la cara de la persona. La detección creada por este método permite la creación de zonas límites en la imagen. Estas zonas son conocidas como “regiones de interés” (roi por sus siglas en inglés). Las roi tienen correspondencia con las partes de donde se piensa extraer las características y medidas que serán la entrada a la red neuronal. Una vez detectada la cara y delimitada las roi, se procede a dibujar un rectángulo alrededor de ella.
- Detección de la boca. Aplicar Haar-like Features Cascades a la roi creada en el paso anterior, para la detección de la boca de la persona y dibujar un rectángulo alrededor de la roi. La imagen delimitada por la roi se convierte a escala de grises. Se le aplica una ecualización de histograma a la imagen delimitada en la roi que permite crear una media de la iluminación de la imagen.
- Establecer límites. Se le aplica un threshold a la imagen delimitada en la roi. El proceso de threshold permite la estipulación de un número, el cual funciona como umbral; en caso de que este umbral sea superado por la cantidad de gris de un pixel dado, el pixel en cuestión se volverá negro, en caso contrario se volverá blanco. Este proceso ocasiona que la imagen se reduzca a solo dos colores, negro y blanco. La imagen delimitada en la roi se guarda en una matriz del tamaño de la imagen en pixeles.
- Coordenadas alrededor de la imagen. En este paso se escanea la imagen y se localizan los pixeles negros en las posiciones más bajas, más a la izquierda, derecha y más altas. Con esto se obtienen cuatro coordenadas (x, y) alrededor de la imagen.
- Detectar ojos. Se aplica Haar-like Features Cascades para detectar los ojos derecho e izquierdo de la persona. Se dibuja un rectángulo alrededor de la nueva roi y se aplican los pasos iii y iv para delimitar los ojos. Respecto a la ceja, se aplica el mismo procedimiento, pero solo se obtienen tres coordenadas.
- Dibujar líneas entre coordenadas. Se dibujan las líneas entre las coordenadas establecidas para cada roi. Estas 22 líneas representan “distancias” que se utilizan para detectar la emoción de la persona (véase la figura 48).
- Para cada una de las 22 distancias, se aplica el teorema de Pitágoras entre las dos coordenadas de cada distancia y se guarda el resultado de la hipotenusa del triángulo. En caso de que el teorema de Pitágoras no se pueda aplicar, ya sea porque los dos puntos están alineados vertical u horizontalmente, se guarda la diferencia positiva entre las dos coordenadas que no son iguales.
- Normalización de valores. Cada una de las 22 distancias se divide por la anchura de la cara. Esta división normaliza los valores de distancia en el intervalo 0 a 1.
- Asignar la emoción. La emoción es el resultado deseado de la red neuronal al usar la expresión del rostro que se representa por una letra de acuerdo con los valores calculados previamente.
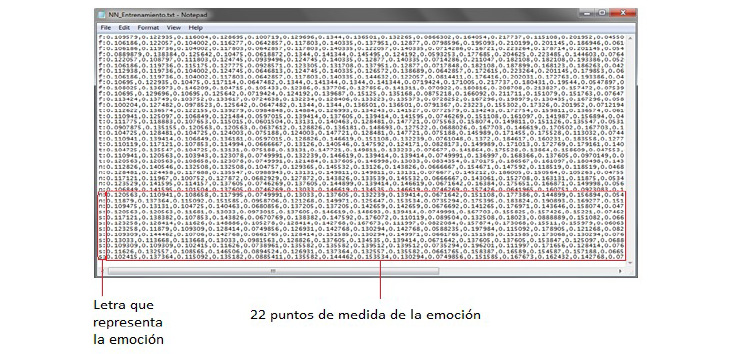
- Almacenar información. Se crea y guarda una nueva línea en un archivo de texto con la letra que representa la emoción y las 22 distancias. La figura 49 muestra una parte del archivo donde cada línea representa las características extraídas de un rostro.
- Finaliza la extracción de características del rostro actual y se repite el proceso con un nuevo rostro o cara.
Figura 48. Rostro con las 22 distancias usadas para reconocer emociones

Figura 49. Archivo con emociones y distancias para entrenar a la red neuronal
Entrenamiento y prueba de la red neuronal de Kohonen
La red neuronal fue entrenada con diferentes conjuntos de datos de caras. En el proceso de entrenamiento y con los resultados obtenidos, se procedió a realizar cambios en la extracción de características y en el algoritmo de entrenamiento de la red. A continuación, se explica cómo se realizó este proceso con diferentes conjuntos de datos.
Conjunto de datos Grimace (https://cmp.felk.cvut.cz/~spacelib/faces/grimace.html)
Contiene un total de 360 imágenes, las cuales se dividen en 18 modelos, cada una con 20 imágenes. Este conjunto de datos presenta a un grupo de individuos, los cuales hacen muecas que son capturadas en fotos. Un ejemplo de estas imágenes se presenta en la figura 50. Dos desventajas de Grimace son que las imágenes no están organizadas por emociones y que tienen una mala iluminación.
Figura 50. Ejemplo de imágenes de la base de datos Grimace

Conjunto de datos JAFFE (https://www.kasrl.org/jaffe_download.html)
Japanese Female Facial Expression es un conjunto de datos de expresiones faciales que contiene 213 imágenes. Estas se dividen en siete expresiones faciales simuladas por diez modelos japonesas femeninas. Las expresiones faciales son: sorpresa, enojo, miedo, disgusto, felicidad, tristeza y neutral. En la figura 51 se observa un ejemplo de estas imágenes. Las desventajas de este conjunto de datos son que solo cuenta con rostros femeninos, que pertenecen a solo una raza (poca variedad), y que están en blanco y negro.
Figura 51. Ejemplo de una modelo mostrando cinco emociones en JAFFE
Conjunto de datos RaFD
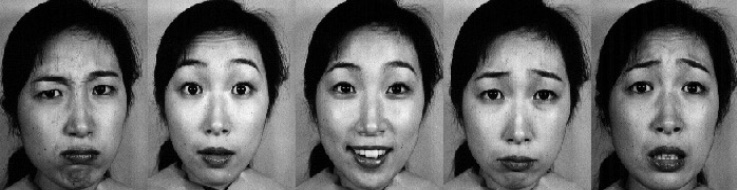
La Radboud Faces Database (Langner et al., 2010) es una base de datos de expresiones faciales pertenecientes a un conjunto de 67 modelos que incluye hombres y mujeres caucásicos, niños y niñas caucásicos y hombres marroquí-holandeses. Los modelos muestran ocho expresiones emocionales, las cuales corresponden al facs de Ekman (Ekman & Freisen, 1978). Un ejemplo de esta base de datos se muestra en la figura 52. La RaFD fue la base de datos que dio mejores resultados para Fermat.
Figura 52. Ejemplo de un modelo mostrando ocho emociones en RaFD

Ejemplo del extractor de características y el entrenamiento de la red neuronal
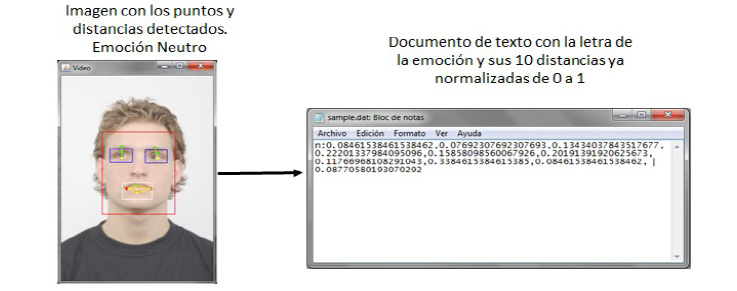
A continuación se describe un ejemplo para mostrar la forma en que el extractor de características captura las distancias y las normaliza. Posteriormente se muestra el procesamiento de la red neuronal. Para el ejemplo se tomó una imagen de la base de datos RaFD (véase figura 53) cuya emoción reconocida es la de neutro (letra n). Primero se señalan los puntos de la cara y se calculan las distancias. Después se normalizan los valores y se guardan en el archivo de texto. En este ejemplo solo aparecen diez distancias almacenadas, que son el resultado de los últimos cambios realizados al algoritmo de extracción de características.
Figura 53. Conversión y normalización de las distancias
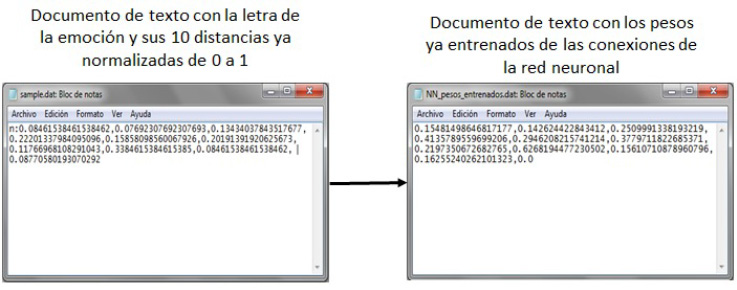
Finalmente se muestra la conversión de las distancias ya normalizadas con los pesos finales de las conexiones generados por la red neuronal (figura 54).
Figura 54. Conversión de las distancias normalizadas a pesos ya entrenados
Tecnologías usadas en el desarrollo
La red social Fermat y los sistemas tutores inteligente para el aprendizaje de operaciones de multiplicación y división de números enteros fueron implementados con diferentes herramientas de software y lenguajes de programación.
La red social Fermat fue implementada usando un modelo arquitectónico de tres capas; en el desarrollo de cada capa se usaron diferentes tecnologías.
La capa de presentación, que es responsable de interactuar con el usuario a través de diferentes dispositivos móviles y de escritorio, se implementó usando el lenguaje de programación JavaScript, el lenguaje de marcas HTML5 y el lenguaje de diseño de hojas de cascada CCS3, permitiendo así la adecuación dinámica del contenido que se presenta al usuario a través de la pantalla del dispositivo que usa.
Por otra parte, la capa lógica del sistema contiene los módulos para gestionar la red social, el sistema tutor inteligente encargado de enseñar las operaciones de multiplicación y división y de reconocer las emociones del usuario. Los componentes de esta capa lógica se desarrollaron usando el lenguaje de programación Java y jsp para la creación de páginas web dinámicas basadas en el lenguaje html y xml para el intercambio de datos. El módulo de gestión del sti contiene la lógica del sistema tutor inteligente y además realiza el reconocimiento de emociones a través de expresiones del rostro captadas en imágenes. El sistema personaliza la instrucción usando en el sistema difuso la información detectada durante la sesión de aprendizaje. La información que se usa en el sistema difuso para determinar el grado de complejidad del siguiente ejercicio consiste en 1) el estado emocional del estudiante, 2) el tiempo invertido en un ejercicio, 3) el número de errores cometidos en la solución de un ejercicio y 4) el número de ayudas o apoyos pedagógicos solicitados por el estudiante durante la sesión.
Finalmente, la capa de datos se implementó a través del manejador de base de datos MySQL y el lenguaje de marcas xml, con el fin de resguardar la información necesaria que almacena los cursos, ejercicios, perfiles de estudiantes, etc., los cuales son indispensables para el correcto funcionamiento del sistema.